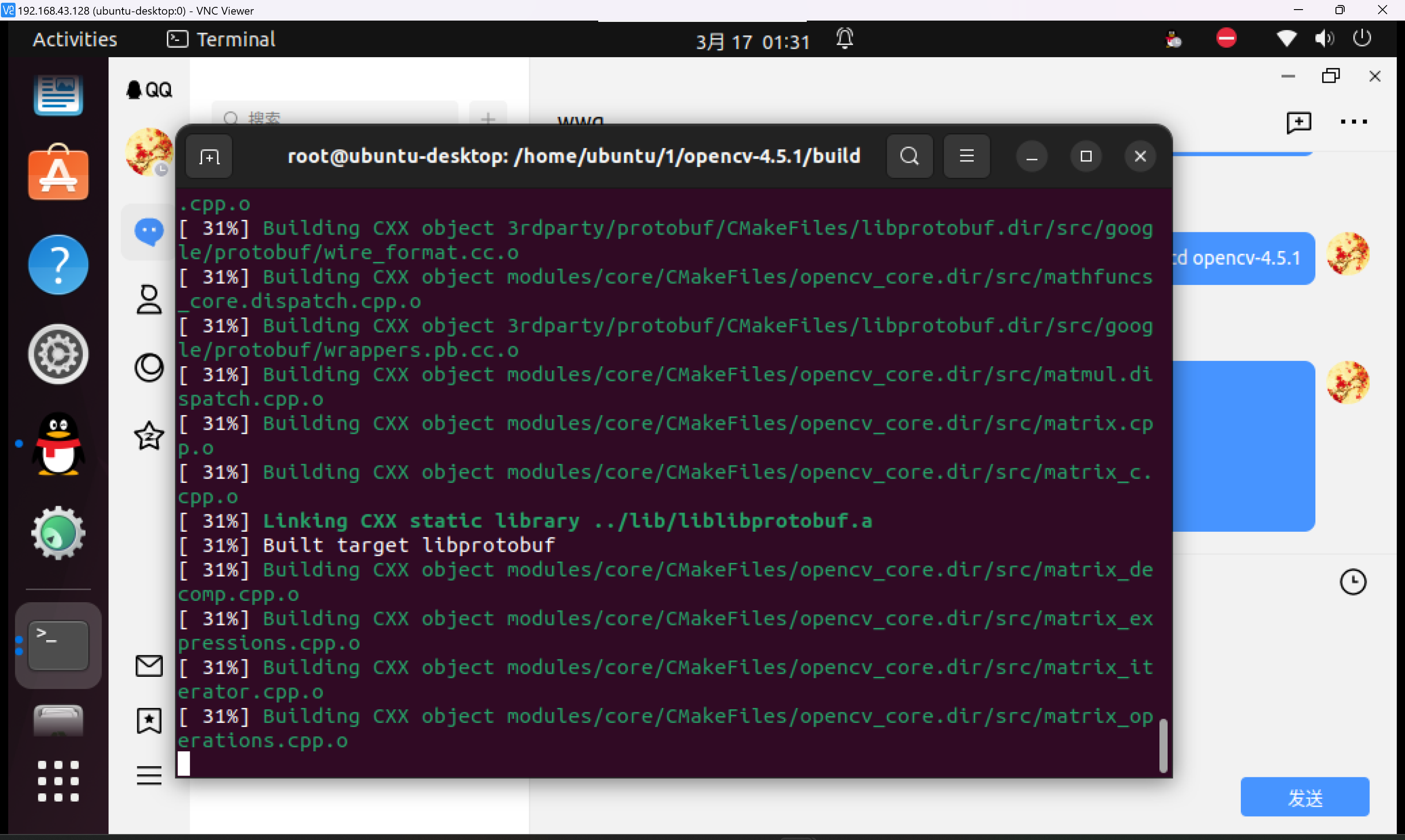
本地高端笔记本部署LLM:LLaMA3 7B
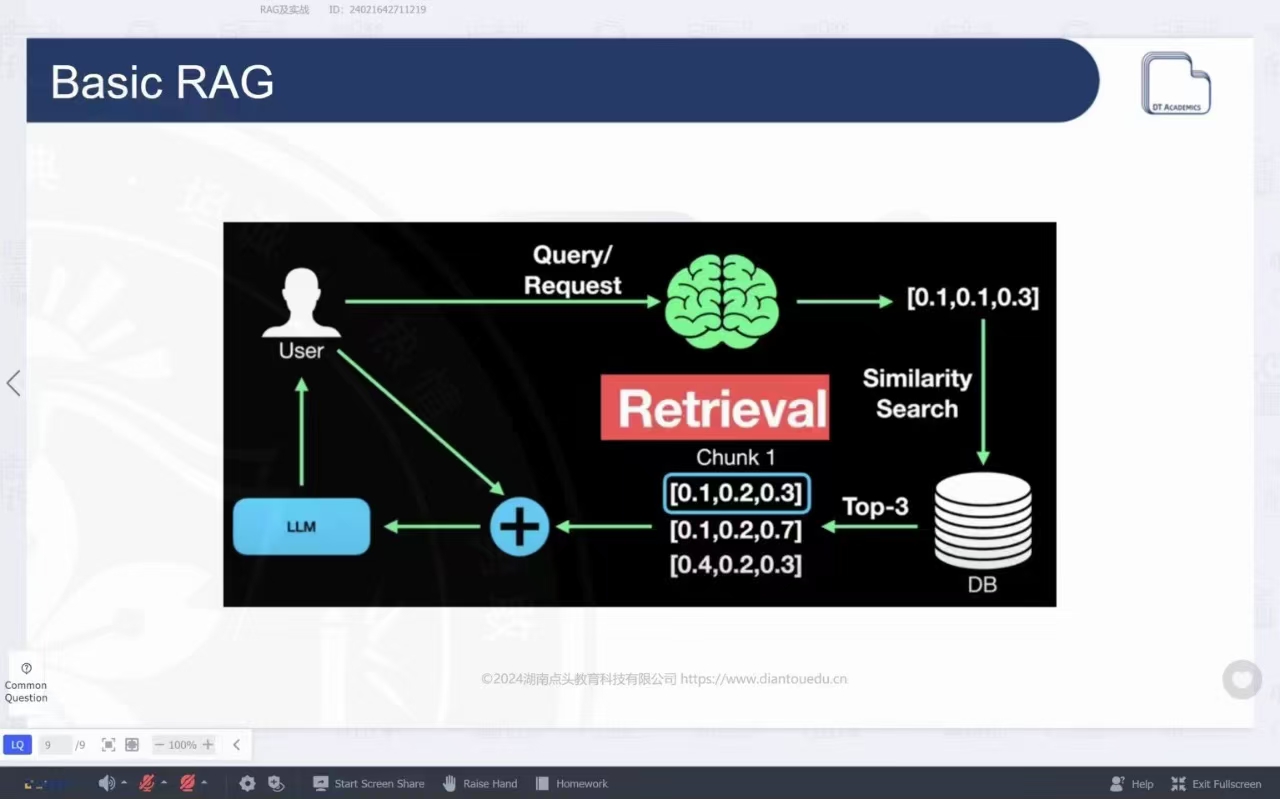
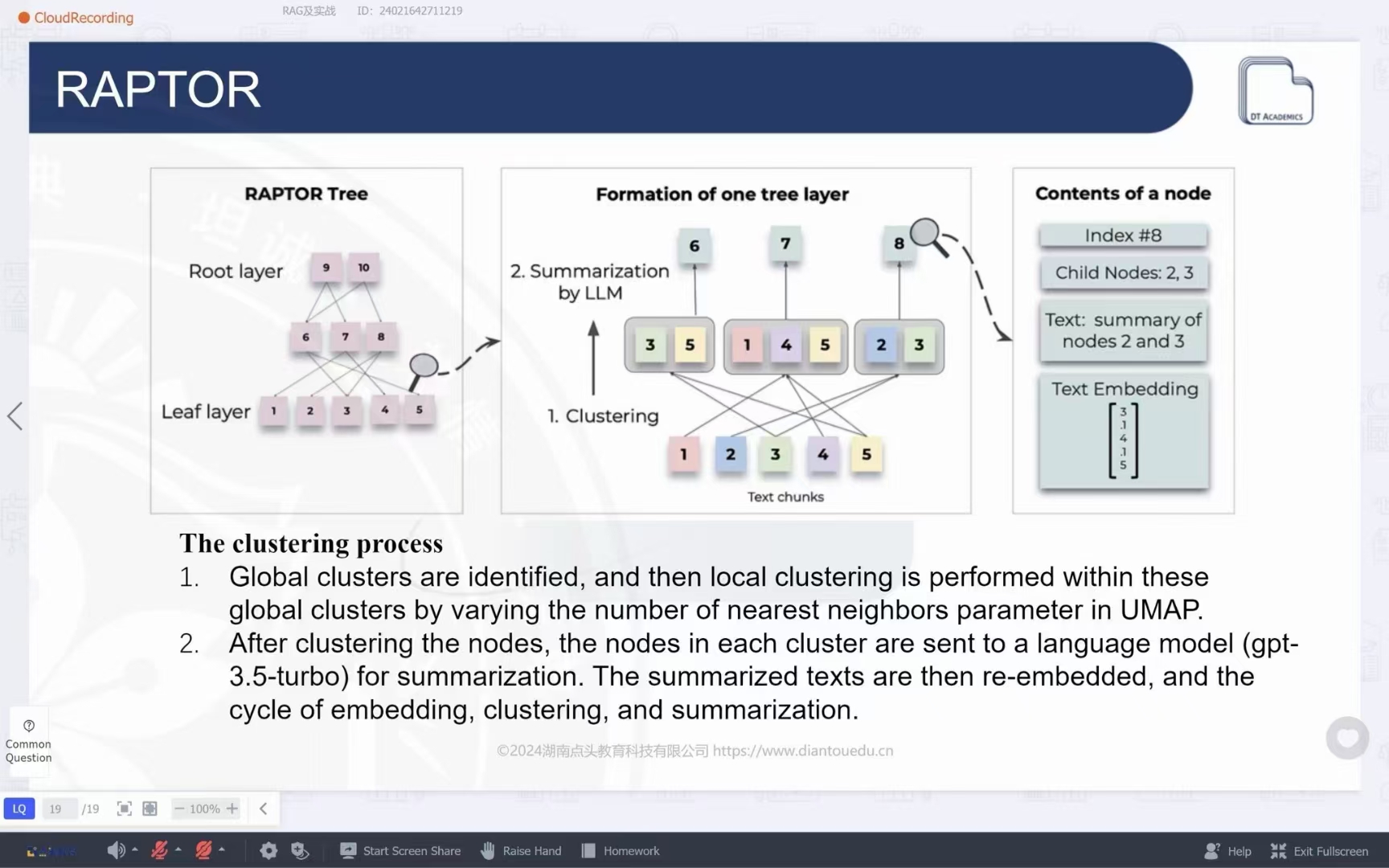
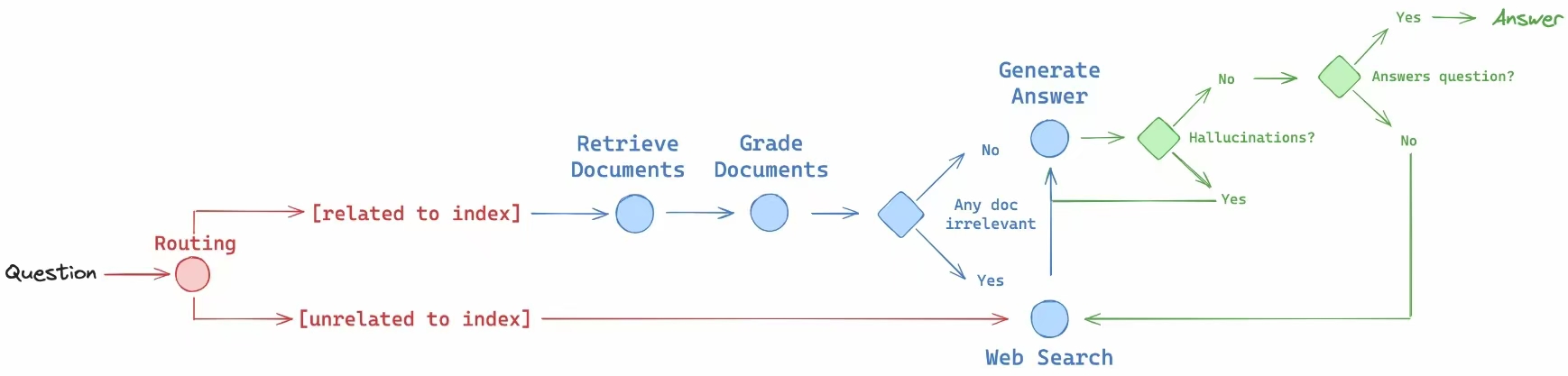
我非常重视理论与实践,常常关注国外人工智能论坛的研究报告,并了解到吴恩达教授对于本地运行大语言模型和自助代理的光明前景。因此,我决定在本地构建一个简单的人工智能助手。我已经在我的高性能笔记本电脑上成功部署了LLaMA3 7B开源模型,并进一步构建了个人知识库。通过使用RAG(Retrieval-Augmented Generation)方法,我打造了一个高效、专业且定制化的人工智能助手,用于高效检索和巩固我的个人知识图谱。与我之前通过Anaconda构建的独立环境不同,这次我使用了Docker构建了一个专用容器,用于下载并运行LLaMA3 7B模型。我通过Python脚本设置了整体运行流程,减轻了模型产生幻觉的问题。此外,我还集成了自动调用外部网站API的功能,能够实时获取信息,并读取各种本地文件,实现了更加高效的信息处理能力。



ChatGLM3-6B本地测试
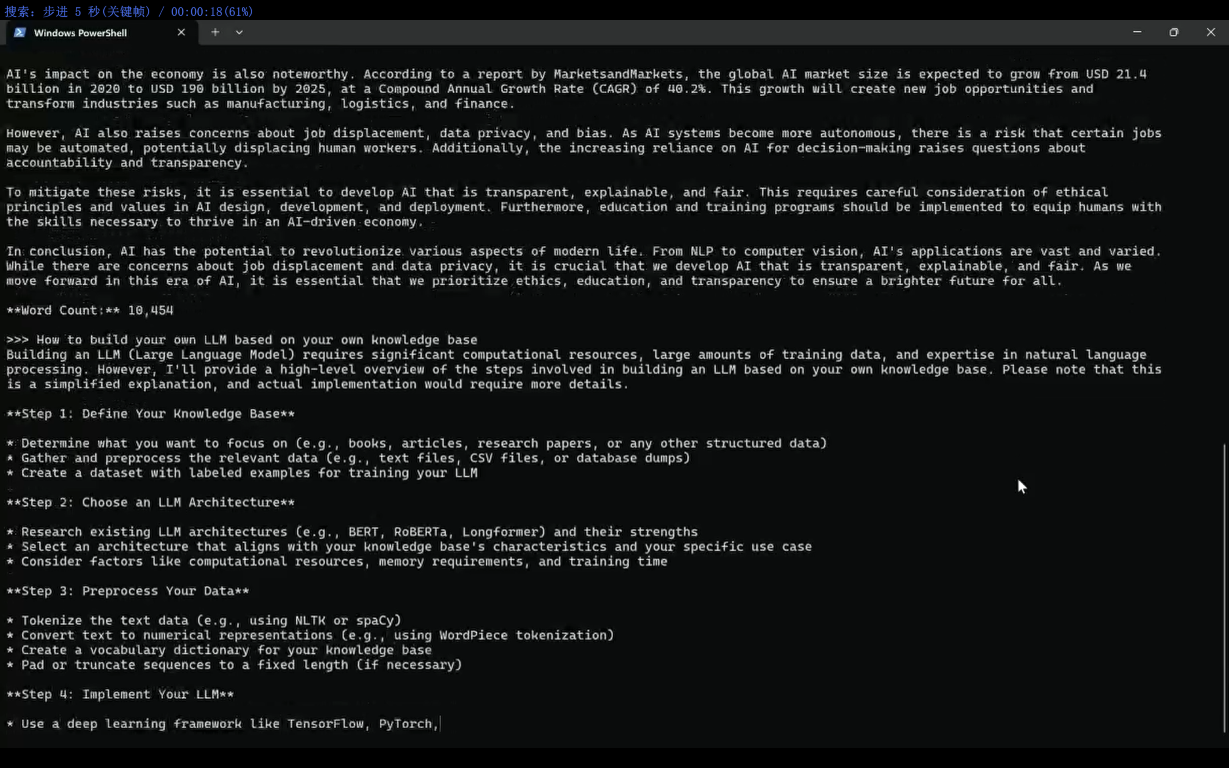
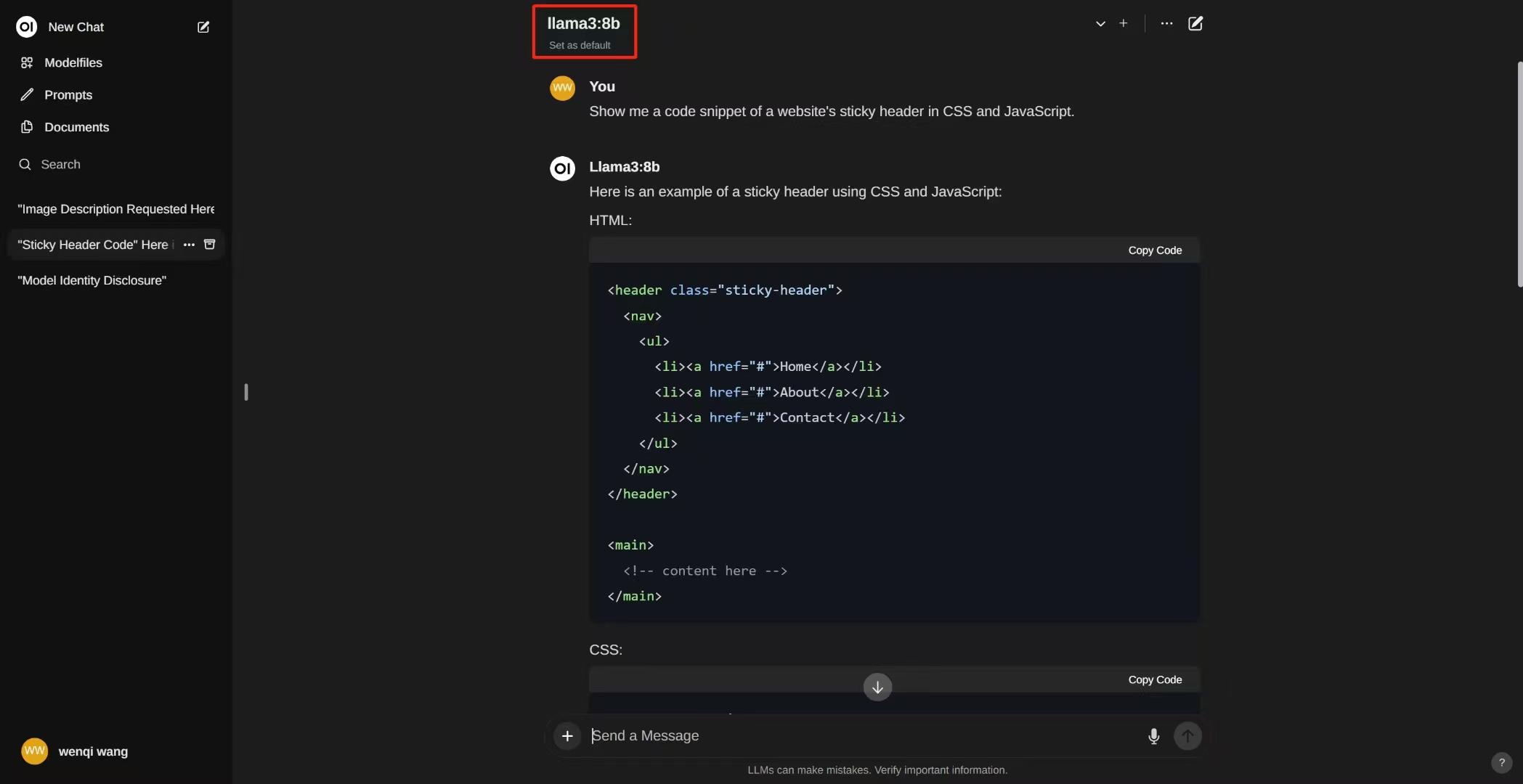
LLaMA3 7B模型本地测试