基于FPGA的CNN加速的目标检测
第七届海云捷迅杯的基于FPGA的机器视觉检测,对于我来说是一个全新的赛道,相比于一些传统的A类竞赛,这个B类竞赛十分新颖,十分有挑战,它涵盖了从卷积神经网络的目标检测,到模型文件的转换 、优化剪枝量化各种算子的转换各种文件和IP核调用 。虽然学习的过程十分艰难,但是学到了很多东西 。虽然没获得理想的结果,但是我还是勇于跨出了这一步,比赛结以前的那次通宵,让我永身难忘和另一位优秀的队友交流学习,对我大有裨益,从它身上学到了很多特别是他解决问题时的思维和激情,使我受益非汝,路漫其修远矣,吾将上下而求索 。
一些学习的基础知识:
- FPGA的组成,结构
- FPGA板载资源
- FPGA设计、验证工具
- ARM 双核A9 调用API IP内核
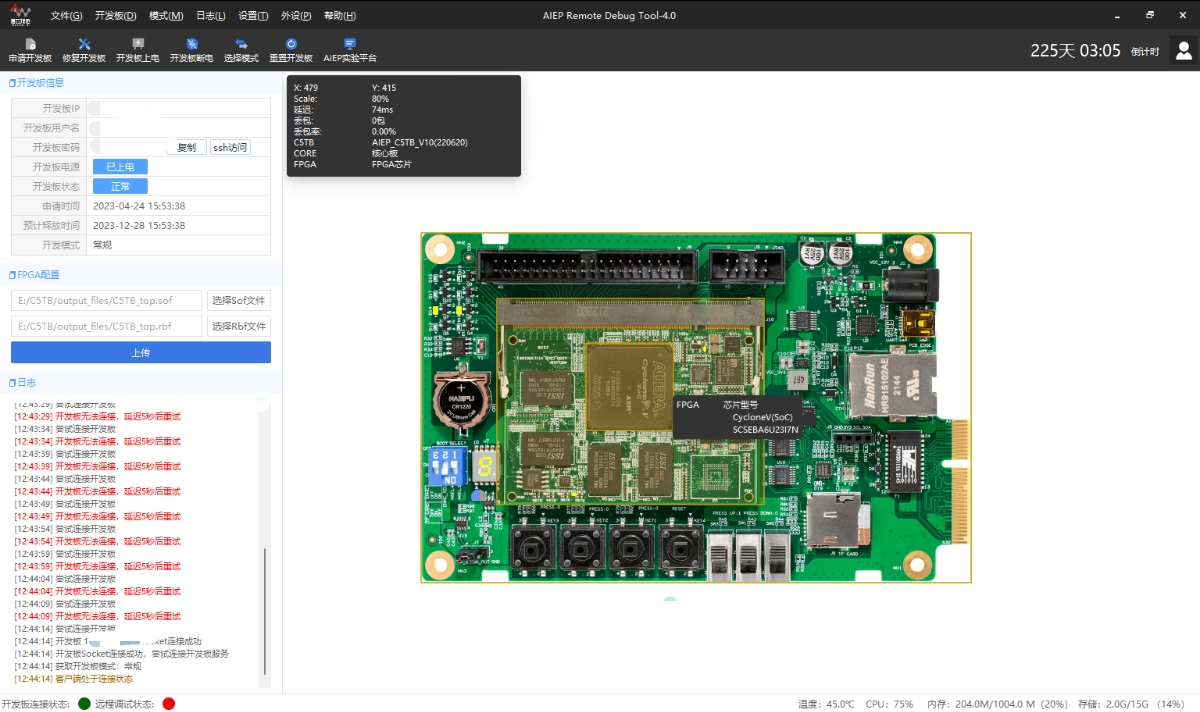
需要SSH远程登陆到云端系统(人工智能边缘实验平台),才可以访问FPGA相关资源,运行程序也需要将其上传到云端之后再加载到实体FPGA开发板上。
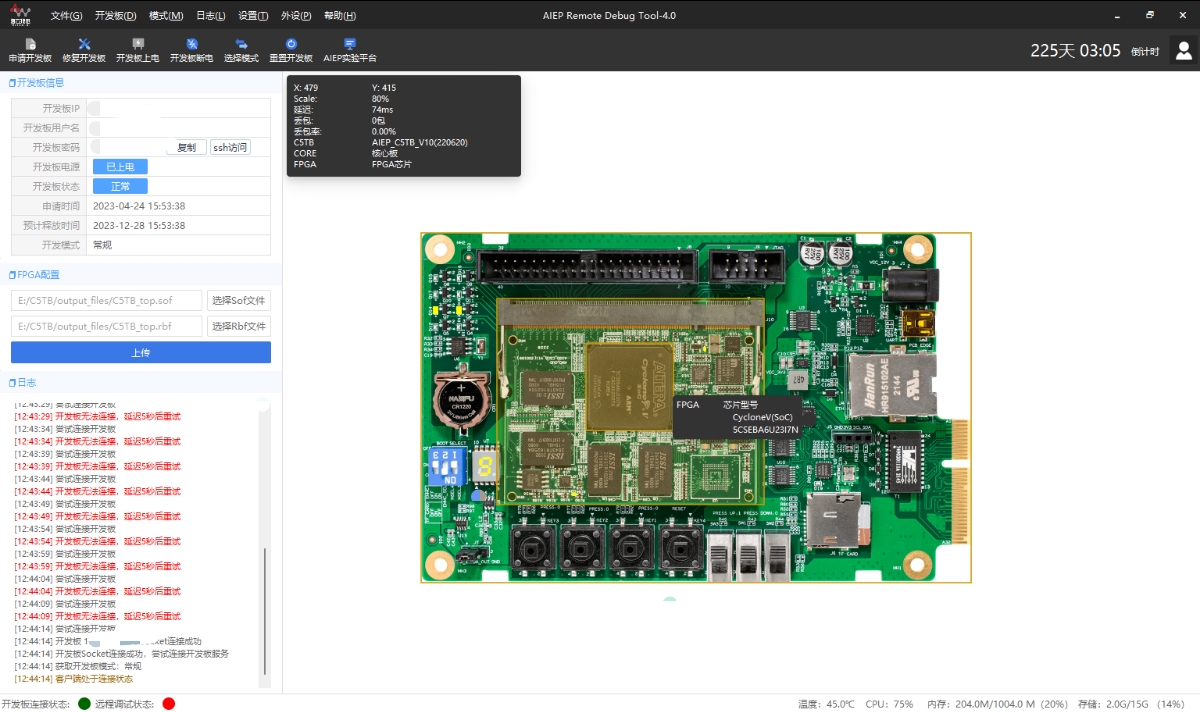
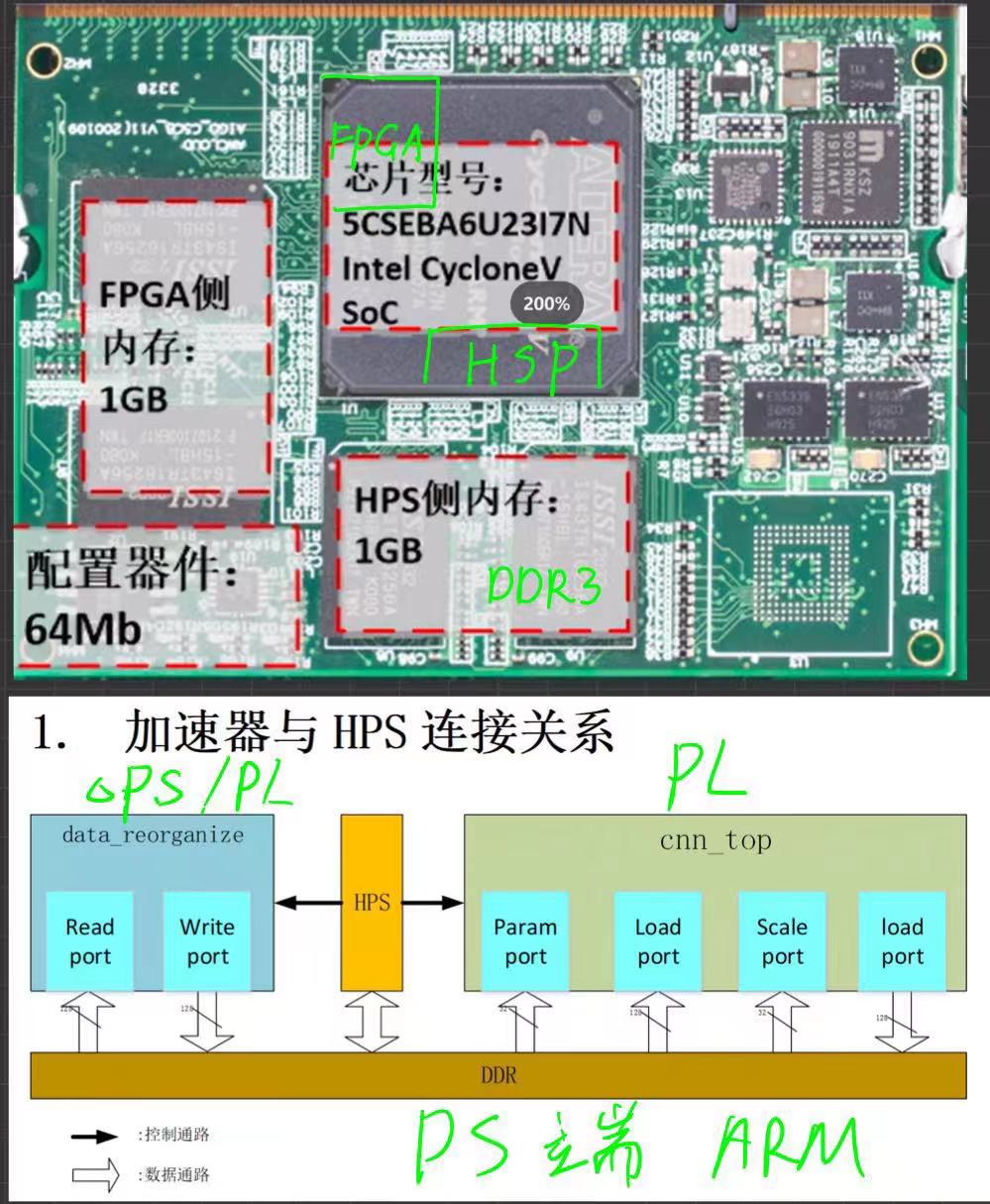
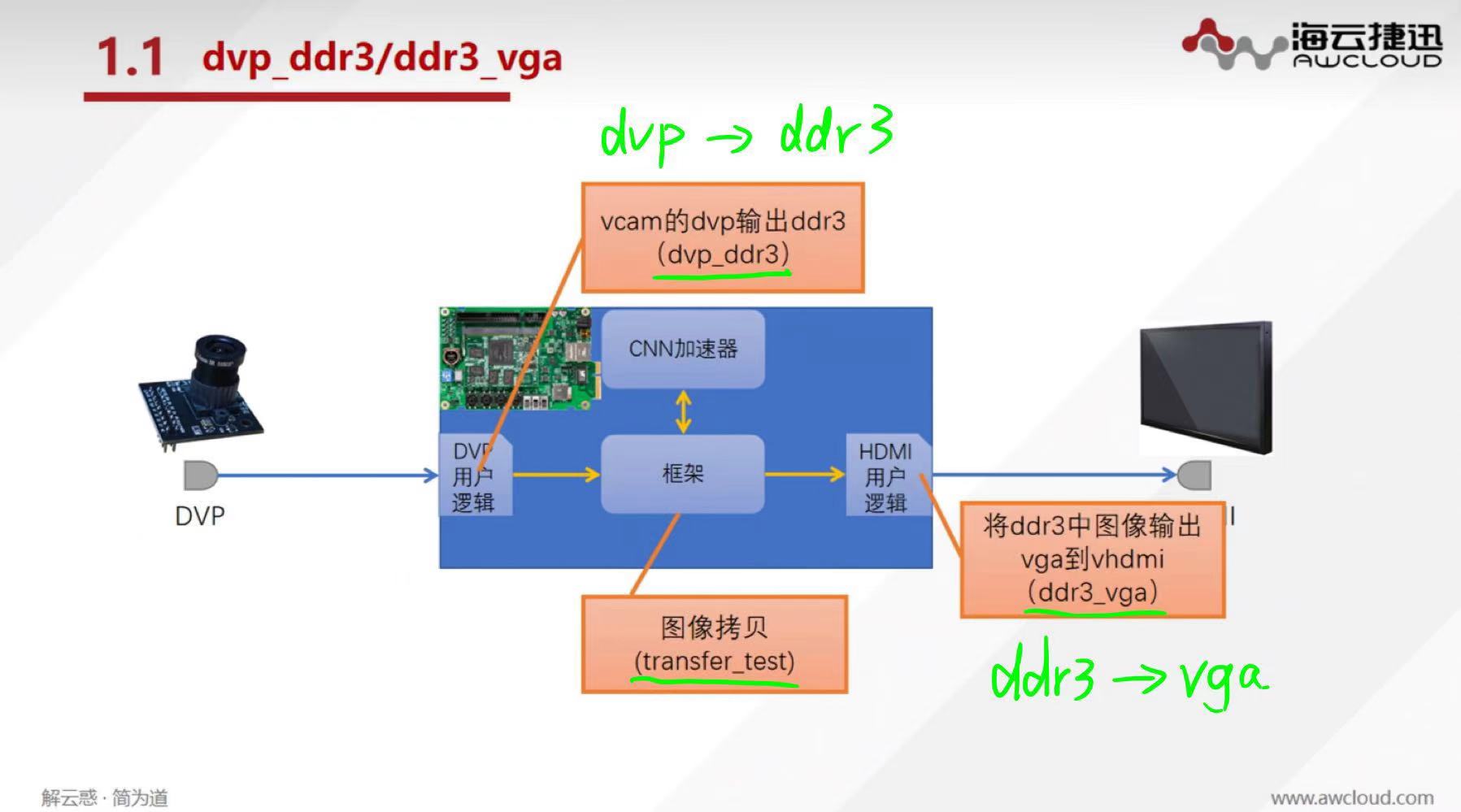




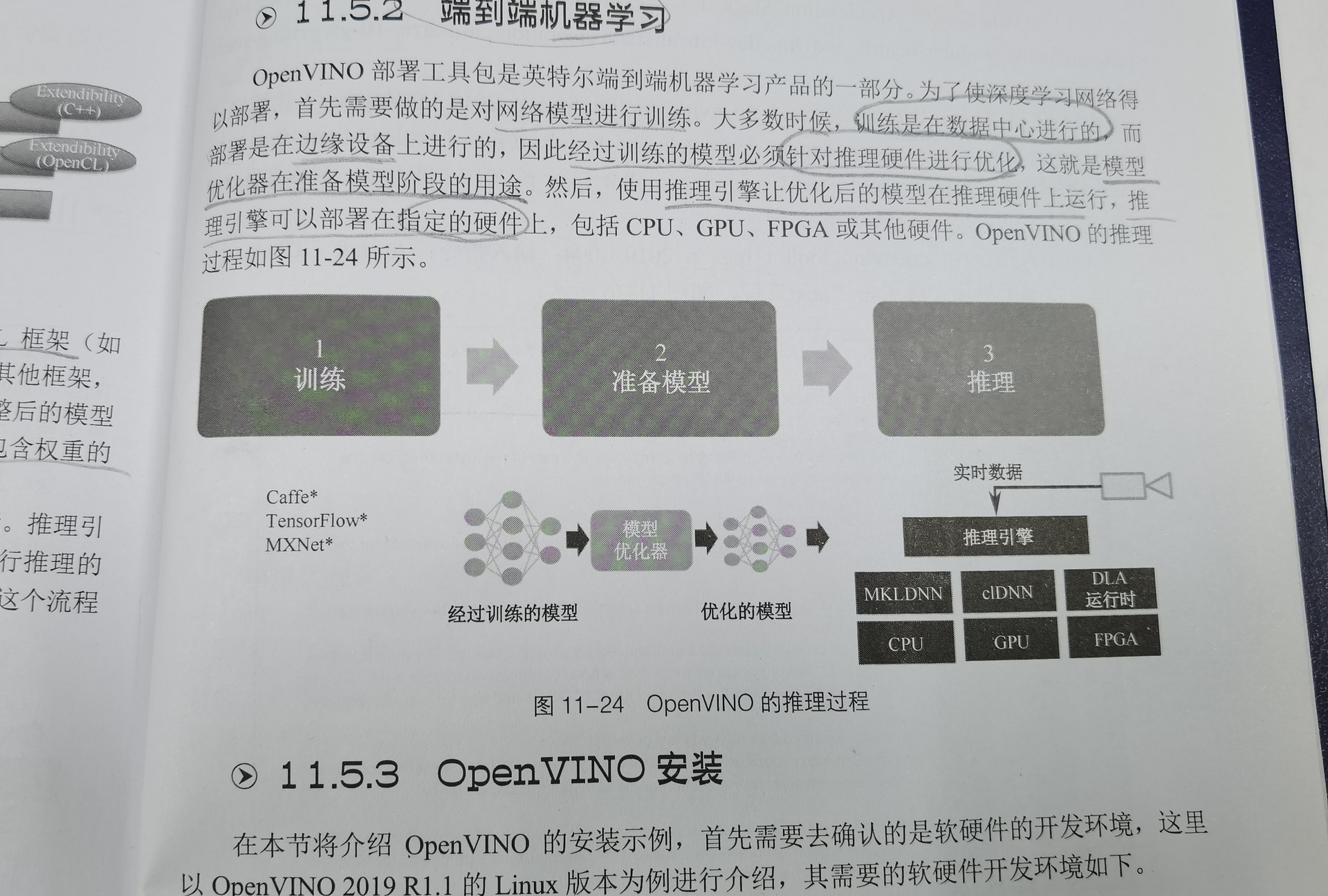
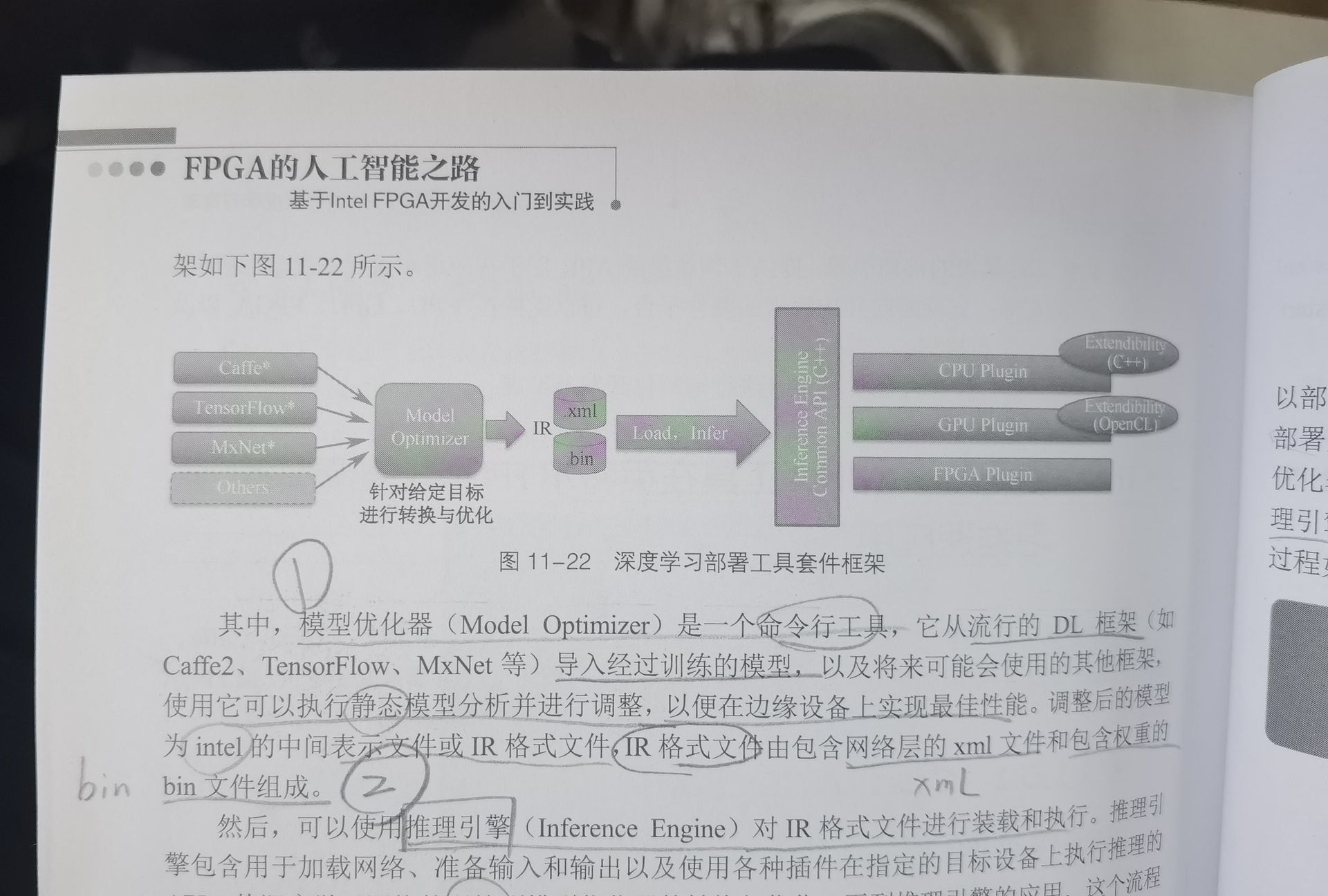
芯片架构主要分为:X86架构和ARM架构。通过以上书本内容的学习加上实践,使我对于芯片架构有了深入的理解,还有异构芯片架构等等概念有了一定的了解,还有模型在芯片中部署,推理的不同阶段过程调用的片内资源是不同的。本次竞赛就是关注与FPGA编程对于CNN图像处理的并行计算加速。
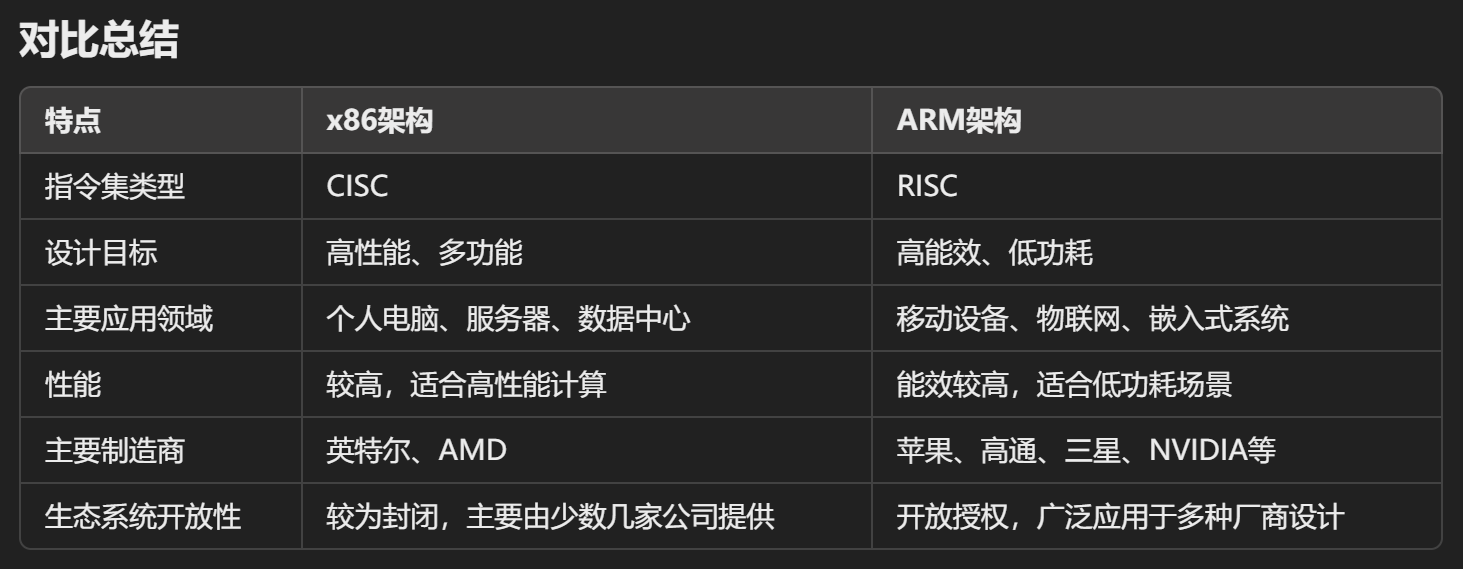
未来发展趋势
- x86架构:英特尔和AMD持续推动x86在高性能计算上的发展,包括向更多核心数、更高频率和更先进的制造工艺进展。随着数据中心和人工智能的快速发展,x86架构仍将在高性能领域保持优势。
- ARM架构:由于其出色的能效比,ARM正在迅速进入新的市场领域。苹果M系列芯片的成功证明了ARM架构在桌面设备中的潜力。此外,ARM在低功耗、移动性和定制化方面的优势也使其成为数据中心和人工智能领域的竞争者,尤其是与NVIDIA等公司合作,推出用于AI加速的ARM架构芯片。
we pulled an all-nighter

从图书馆借了很多关于intel FPGA相书籍和深度学习及机器学习,为了可以更好更快速的下载github仓库的代码还选择使用了各种源,有的是官方的源(中国大陆使用下载速度很慢),有的是清华大学的源(镜像)下载速度更快。